# Build scale by Cronbach 's alpha
(Viết nội dung hướng dẫn tại đây). Tham khảo markdown
# Khái niệm thang đo
Thang đo: là tạo ra một thang điểm để đánh giá đặc điểm của đối tượng nghiên cứu thể hiện qua sự đánh giá, nhận xét.
Biến định tính: Một tính trạng nào đó. Vd: giới tính, cảm nhận,
Biến định lượng: Đo được bằng một con số cụ thể. Vd: thu nhập, doanh thu,…
4 loại thang đo, mỗi thang đo sau kế thừa đặc điểm của thang đo trước và thêm một đặc điểm bổ sung:

Thang đo danh nghĩa: Gán cho biến định tính một biến giả, cốt chỉ để phân biệt, không có sự so sánh hơn kém. Vd: Nam = 1, Nữ = 0.
Thang đo thứ bậc: Giống như danh nghĩa nhưng có sự so sánh, nhưng sự chênh lệch giữa 1 và 2 khác sự chênh lệch giữa 3 và 4. Vd: Cổ phiếu 2 tốt hơn cổ phiếu 1 nhưng sự khác biệt giữa 1 và 2 không giống sự khác biệt giữa 2 và 3.
Thang đo khoảng: Sự khác biệt là bằng nhau, nhưng điểm "0" là abitrary. Vd: đối với nhiệt độ, 0 độ C không có nghĩa là không có nhiệt độ.
Thang đo tỷ lệ: Mang đầy đủ 3 tính chất của thang đo trước và điểm 0 thực sự có ý nghĩa, nhưng khó sử dụng trong điều tra xã hội cũng như kinh tế, thường được dùng trong vật lý đo kg, mét. Vd: với vận tốc 0km/h biểu thị vật đang đứng yên.
Tham khảo thêm: Các loại thang đo trong thống kê
# Kiểm định
# Cronbach's Alpha
α ≥ .60: Không tốt, chấp nhận được
.70 ≥ α ≥ .90: Tốt
α ≥ .95: Không tốt, chấp nhận được
Về cơ bản, hệ số Cronbach’s Alpha đo lường tỉ lệ phân tán của từng nhóm quan sát so với tỉ lệ phân tán của mẫu.
# Phân tích nhân tố EFA
| Giá trị phân biệt | Giá trị hội tụ |
|---|---|
| Từng nhóm quan sát độc lập nhau, người tham gia khảo sát phân biệt được từng nhân tố khác nhau. Khi biểu diễn trong ma trận xoay, từng nhân tố tách thành các cột riêng riệt | Các biến quan sát hội tụ về một nhân tố. Từng yếu tố trong một nhóm quan sát chỉ thuộc về nhóm đó và góp phần tạo nên khái niệm của nó. Khi biểu diễn trong ma trận xoay, các biến này nằm chung một cột với nhau. |
Trong phân tích nhân tố, phương pháp Principal Components Analysist đi cùng với phép xoay Varimax được sử dụng để nhóm các biến quan sát cùng miêu tả một khái niệm lại với nhau. Hệ số tải (factor loading) là một đại lượng đặc trưng để đảm bảo mức ý nghĩa thiết thực của EFA.
Factor loading thể hiện phần trăm phương sai mà một biến trong nhóm quan sát đó được giải thích bởi nhân tố đó.
Theo Hair & CTG trong Multivariate Data Analysis (1998), nếu cỡ mẫu lần lượt là 50, 100, 350 thì lần lượt tương ứng với hệ số tải là .75, .55 và .3
KMO and Barlett’s test: “KMO là một chỉ tiêu dùng để xem xét sự thích hợp của EFA, phân tích nhân tố khám phá (EFA) thích hợp khi 0,5 ≤ KMO ≤ 1. Kiểm định Bartlett xem xét giả thuyết về độ tương quan giữa các biến quan sát bằng 0 trong tổng thể, nếu kiểm định này có ý nghĩa thống kê (sig ≤ 0,05) thì các biến quan sát có tương quan với nhau trong tổng thể.” (Ngọc, 2005)
# Thiết kế nghiên cứu
# Quy trình
Phỏng vấn định tính để xây dựng bảng câu hỏi => Tiến hành khảo sát định lượng.
# Chọn mẫu:
Về cơ bản thì cỡ mẫu càng gần với tổng thể càng tốt. Nhưng trong thực tế, nếu tổng thể quá lớn thì rất khó để chọn cỡ mẫu gần tổng thể nên người ta chọn nghiên cứu những mẫu quan sát bao gồm các đặc trưng của tổng thể.
Có 2 cách chọn mẫu:
Xác suất: mỗi phần tử trong tổng thể có xác suất được chọn vào mẫu bằng nhau.
Phi xác suất: Mỗi phần tử trong tổng thể có xác suất được chọn khác nhau.
Chọn mẫu xác suất:
| Phương pháp | Định nghĩa | Ưu | Nhược |
|---|---|---|---|
| Ngẫu nhiên đơn giản | Đánh số thứ tự các phần tử. Chọn ngẫu nhiên | Tính đại diện cao | Tốn kém và mất thời gian |
| Chọn mẫu hệ thống | Như trên nhưng chọn cách đều các phần tử | // | // |
| Phân tổ/tầng | Chia tổng thể thành một hay nhiều tổ liên quan đến mục đích nghiên cứu. Chọn ngẫu nhiên hoặc hệ thống mẫu trong từng tổ, cỡ mẫu bằng tỷ lệ của tổ đó so với tổng thể. | Tính đại diện cao, ít tốn kém => phổ biến nhất. | |
| Tích tụ hoặc tập trung | Phân tổng thể thành từng khối rồi chọn ngẫu nhiên hoặc hệ thống một (số) khối để điều tra Không cần lập danh sách tổng thể | Tính đại diện chưa cao | |
| Nhiều giai đoạn |
Chọn mẫu phi xác suất:
| Phương pháp | Định nghĩa | Ưu | Nhược |
|---|---|---|---|
| Thuận tiện | Chọn những phần tử thuận tiện, dễ tiếp cận. | Ít tốn kém, thuận tiện | Tính đại diện chưa cao, không kết luận cho tổng thể được. |
| Phán đoán | // | // | Tốt hơn một chút nhưng vẫn không kết luận cho tổng thể được. |
| Định mức | |||
| Tích luỹ nhanh | Bắt đầu từ 1 phần tử rồi nhờ họ giới thiệu những người khác có cùng đặc tính. | Giải quyết mẫu khó tìm, khó tiếp cận |
# Chỉ dẫn SPSS
# Cronbach's Alpha
Bước 1: Analyze => Scale => Reliability Analysis
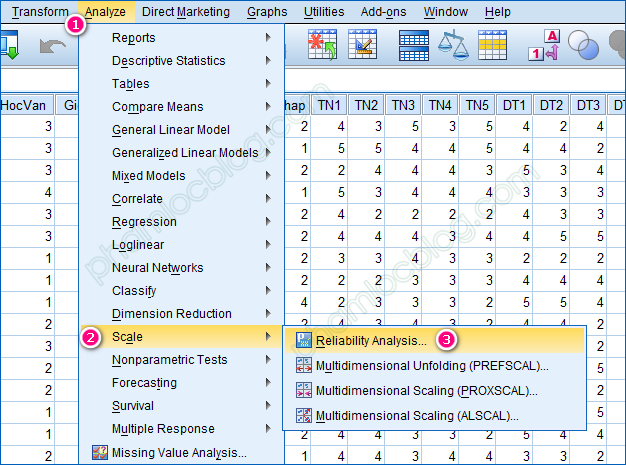
Bước 2: Chọn các quan sát thuộc 1 nhóm nhân tố, lần lượt lặp lại với số lượng nhân tố còn lại

Bước 3: Click chọn Statistic và chọn "Scale if item deleted. Nó cho phép ta xem xét hệ số Cronbach của mô hình khi biến quan sát này bị xóa, ta có thể xem xét loại khỏi mô hình nếu hệ số tăng đáng kể và chắc chắc loại nếu hệ số < .3
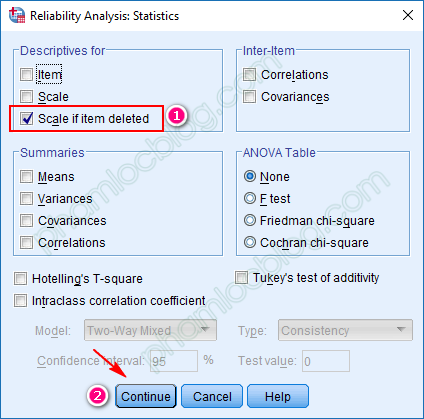
Bước 4: Bấm OK và xuất ra kết quả:
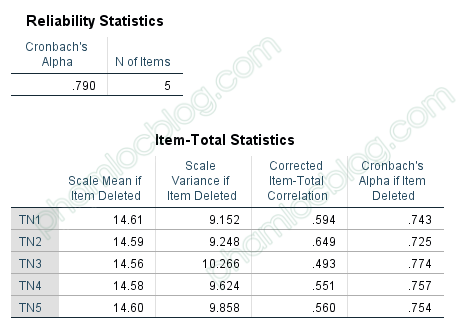
Hệ số Cronbach Alpha của mô hình phải lớn hơn .6 và Corrected Item - Total Correlation phải tối thiểu lớn hơn .3
# EFA
Bước 1: Analyze => Dimension Reduction => Factor
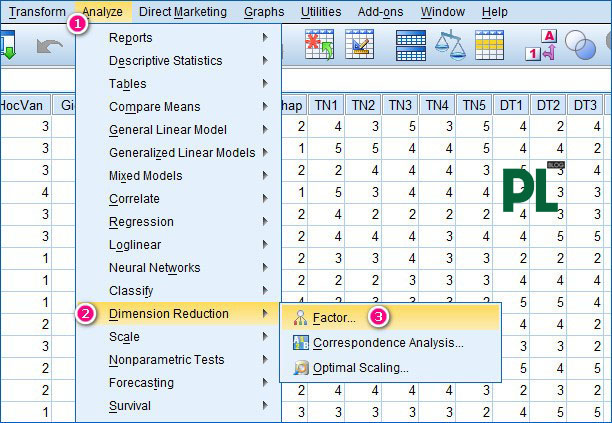
Bước 2: Click chọn tất cả các biến quan sát. Tip: Chọn biến đầu và Ctrl + biến cuối để chọn tất cả các biến. Lưu ý chọn 4 trường Descriptive, Extraction, Rotation, Option
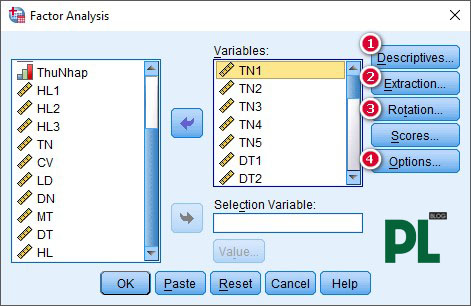
Bước 3: Descriptive: tick vào KMO và Barlett để hiện bảng kết quả. Chọn Continue để quay về bảng chính
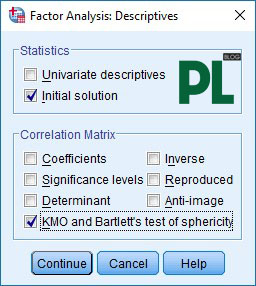
Bước 4: Extraction:
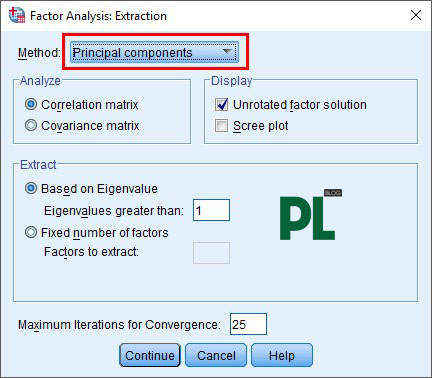
Bước 5: Rotation: phép quay Varimax
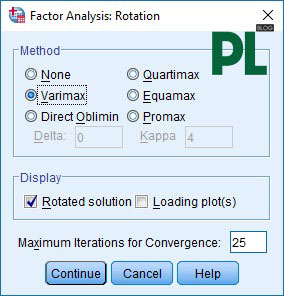
Bước 6: Option: Sorted by size: biểu diễn ma trận dạng bậc thang. Supress: loại bỏ các biến có hệ số factor loading < .3. Absolute value: min threshold của factor loading
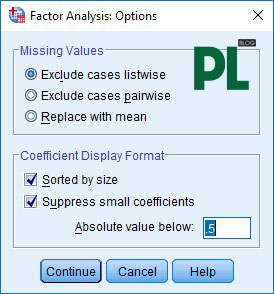
Bước 7: OK và xuất output
Chỉ cần quan tâm 3 bảng: KMO và Barlett: Sig < 0.05 Total Variance Explained: Xem tổng phương sai trích và giá trị Eigenvalue Rotated Components Matrix: Tồn tại một quan sát nào mà có hệ số tải lên 2 nhóm trở lên